Vzhled
2 • Algoritmus
Algoritmus, vlastnosti, zápis, algoritmická složitost
Co je algoritmus
Algoritmus je konečná posloupnost přesně definovaných kroků (instrukcí), které vedou k vyřešení určitého problému. Popisuje postup tak, aby ho mohl provést člověk i počítač, nezávisle na konkrétním programovacím jazyce.
Historie pojmu
Slovo "algoritmus" pochází z přepisu jména perského matematika al-Chvárizmí (cca 780–850 n. l.), který napsal knihu o aritmetických postupech. Z arabského "al-Khwarizmi" se latinizací stal "Algorismi", a odtud dnešní "algoritmus".
Moderní teorii algoritmů formalizoval ve 20. století Alan Turing (Turingův stroj) a později Donald Knuth ve své monumentální sérii The Art of Computer Programming.
Algoritmus ≠ program
| Algoritmus | Program | |
|---|---|---|
| Co je | Abstraktní postup | Konkrétní implementace |
| Forma | Pseudokód, diagram, slova | Zdrojový kód v jazyce |
| Závisí na | Logice problému | Jazyce, prostředí, knihovnách |
| Příklad | "Najdi nejmenší prvek pole" | Math.min(...arr) v JavaScriptu |
Algoritmus je něco jako recept: program je konkrétní vaření podle něj.
Algoritmus ≠ heuristika
| Algoritmus | Heuristika | |
|---|---|---|
| Garance | Vrátí správný výsledek | Pravděpodobně blízko správného |
| Použití | Když máš čas a chceš přesnost | Když potřebuješ rychlost |
| Příklad | Dijkstra: nejkratší cesta | A*: rychlá ale ne vždy optimální |
Vlastnosti algoritmu
Klasické vlastnosti, kterými musí každý algoritmus splňovat (7):
| Vlastnost | Popis |
|---|---|
| Konečnost (finitnost) | Musí skončit po konečném počtu kroků. Nesmí běžet věčně. |
| Resultativnost (výslednost) | Musí vrátit výsledek, nebo oznámit, že řešení neexistuje. |
| Jednoznačnost (determinismus) | Každý krok je přesně definován. Stejný vstup = stejný výstup. |
| Vstupnost | Má jasně definované vstupy, žádné skryté/externí proměnné. |
| Obecnost | Řeší celou třídu problémů, ne jen jeden konkrétní případ. |
| Správnost | Prokazatelně dává správný výsledek pro všechny vstupy. |
| Efektivnost | Co nejméně kroků a paměti. Doběhne v rozumném čase. |
Pseudo-náhodné algoritmy
Některé algoritmy záměrně používají pseudonáhodnost (Quicksort s náhodným pivotem, hashing). Stále jsou deterministické: pokud zafixuješ random seed, dostaneš stejný výsledek. Při různých seedech ale různé pořadí operací.
Zápis algoritmu
Přirozený jazyk
1. Vezmi první prvek seznamu a označ ho jako "nejmenší".
2. Procházej zbytek seznamu.
3. Pokud najdeš menší prvek, označ ho jako "nejmenší".
4. Po projití celého seznamu vrať označený prvek.Plus: čitelné pro každého. Mínus: nepřesné, nekonkrétní, jazyk je víceznačný.
Pseudokód
Strukturovaný zápis podobný kódu, ale bez syntaxe konkrétního jazyka.
function NajdiMin(pole):
min = pole[0]
for i from 1 to length(pole) - 1:
if pole[i] < min:
min = pole[i]
return minPlus: přesný, ale flexibilní. Mínus: žádný standard, každý si píše po svém.
Vývojový diagram (flowchart)
Grafické znázornění pomocí bloků a šipek.
| Tvar | Význam |
|---|---|
| Ovál | Start / konec |
| Obdélník | Operace, příkaz |
| Kosočtverec | Podmínka (rozhodnutí) |
| Rovnoběžník | Vstup / výstup |
| Šipky | Tok programu |
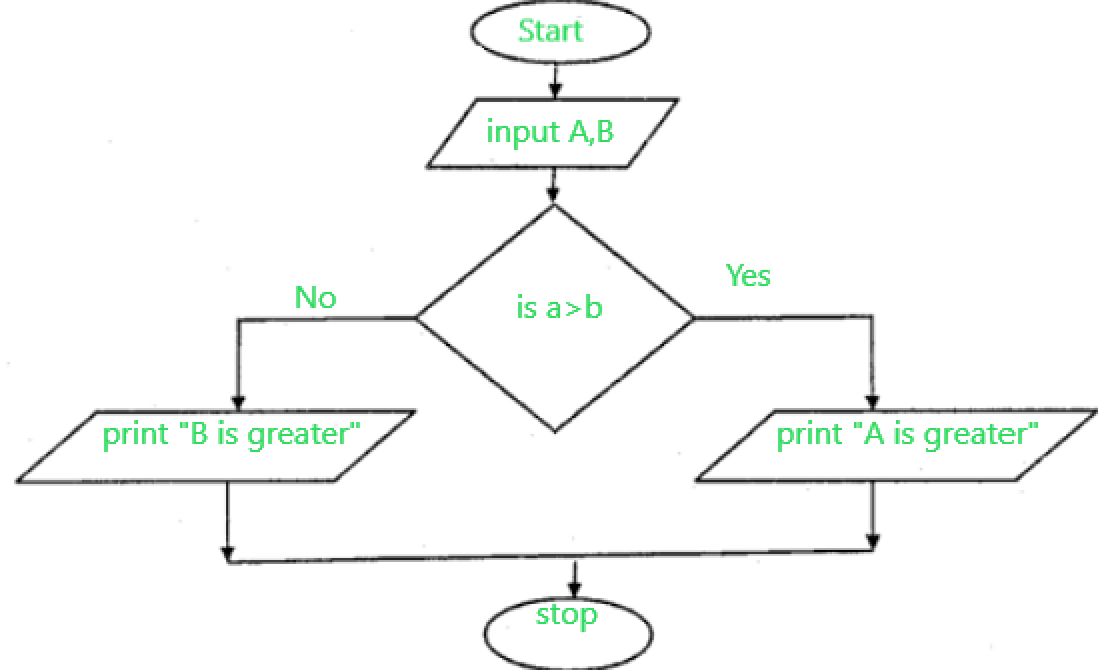
Plus: vizuální, dobré pro výuku. Mínus: pro složité algoritmy nepřehledné.
Zdrojový kód
python
def najdi_min(pole):
min_val = pole[0]
for x in pole[1:]:
if x < min_val:
min_val = x
return min_valPlus: spustitelný. Mínus: vázaný na jazyk.
Typy algoritmů
Podle způsobu řešení
| Typ | Princip | Příklad |
|---|---|---|
| Iterační | Cyklus opakuje kroky | for, while faktoriál |
| Rekurzivní | Funkce volá sama sebe | Rekurzivní faktoriál, traversal stromu |
Iterační faktoriál
python
def factorial(n):
result = 1
for i in range(2, n + 1):
result *= i
return resultRekurzivní faktoriál
python
def factorial(n):
if n == 0: # base case (nutný!)
return 1
return n * factorial(n - 1)Důležité: rekurzivní funkce MUSÍ mít base case (případ ukončení). Bez něj se zacyklí, dojde paměť na zásobníku a program spadne se stack overflow.
Iterace vs rekurze
| Iterace | Rekurze | |
|---|---|---|
| Paměť | Konstantní | Roste s hloubkou zanoření |
| Rychlost | Typicky rychlejší | Pomalejší (volání funkce) |
| Čitelnost | Imperativní | Často elegantnější (stromy, fraktály) |
| Risk | Žádný zvláštní | Stack overflow při hluboké rekurzi |
| Optimalizace | Žádná speciální | Tail-call optimization (ne všude) |
Některé problémy jsou přirozeně rekurzivní (binární strom, Quicksort, fraktály), jiné iterativní (sumy, průměry).
Podle účelu
| Typ | Příklady |
|---|---|
| Výpočetní | Faktoriál, mocnina, Fibonacci, Eukleidův algoritmus |
| Třídicí | Bubble Sort, Merge Sort, Quick Sort |
| Vyhledávací | Lineární, binární, hashování |
| Grafové | Dijkstra, BFS, DFS, A* |
| Šifrovací | AES, RSA, SHA-256 |
| Komprese | LZ77, Huffmanovo kódování |
| Strojové učení | Lineární regrese, k-means, neuronové sítě |
Algoritmická složitost
Složitost popisuje, jak rychle roste zdroje (čas nebo paměť) potřebné pro algoritmus s rostoucí velikostí vstupu n.
Časová vs prostorová složitost
| Časová složitost | Prostorová složitost | |
|---|---|---|
| Měří | Kolik operací algoritmus provede | Kolik paměti potřebuje |
| Označení | Stejné notace (O, Ω, Θ) | Stejné notace |
| Příklad | Bubble sort: O(n²) | Bubble sort: O(1) (in-place) |
| Příklad | Merge sort: O(n log n) | Merge sort: O(n) (potřebuje extra pole) |
Často jde proti sobě: rychlejší algoritmus může potřebovat víc paměti (memoizace v DP).
Asymptotická notace
Drobnost k opravě původních zápisků: "Big O notace popisuje nejhorší případ" je zjednodušení. Tady je random Claude ego-tripping bullshit, kterej 100% nebude zajímat komisi:
| Notace | Význam | Analogie |
|---|---|---|
| Big O O(f(n)) | Horní odhad růstu | "Nejhůř roste jako..." |
| Big Omega Ω(f(n)) | Dolní odhad růstu | "Nejmíň roste jako..." |
| Big Theta Θ(f(n)) | Těsný odhad růstu | "Roste přesně jako..." |
V praxi se ale Big O používá pro worst case time complexity jako default. Když řekneš "Bubble Sort je O(n²)", je to konvenčně worst case.
Best, worst a average case
| Algoritmus | Worst | Space |
|---|---|---|
| Quick Sort | O(n²) | O(log n) |
| Merge Sort | O(n log n) | O(n) |
| Bubble Sort | O(n²) | O(1) |
| Insertion Sort | O(n²) | O(1) |
| Binary Search | O(log n) | O(1) |
Třídy složitosti od nejlepší po nejhorší
| Notace | Název | Příklad operace |
|---|---|---|
| O(1) | Konstantní | Přístup k prvku pole, hashmap lookup |
| O(log n) | Logaritmická | Binární vyhledávání, balanced tree ops |
| O(n) | Lineární | Procházení pole, lineární vyhledávání |
| O(n log n) | Linearitmická | Efektivní třídění (Merge, Quick, Heap) |
| O(n²) | Kvadratická | Bubble Sort, vnořené cykly |
| O(n³) | Kubická | Naivní násobení matic |
| O(2ⁿ) | Exponenciální | Generování všech podmnožin, brute force |
| O(n!) | Faktoriální | Generování všech permutací, traveling salesman brute |
Pravidla zjednodušování
- Drop konstanty: O(2n) → O(n), O(3n²) → O(n²)
- Drop nižší řády: O(n² + n) → O(n²)
- Suma cyklů: O(n) + O(m) = O(n + m), často zjednodušeno na O(max(n, m))
- Násobek vnořených cyklů: O(n) × O(m) = O(n · m)
Klasické algoritmy k zapamatování
Fibonacci
python
# Naivně rekurzivně: O(2^n), pomalé
def fib(n):
if n < 2: return n
return fib(n-1) + fib(n-2)
# S memoizací (dynamic programming): O(n)
def fib_dp(n, cache={}):
if n in cache: return cache[n]
if n < 2: return n
cache[n] = fib_dp(n-1, cache) + fib_dp(n-2, cache)
return cache[n]
# Iterativně: O(n) čas, O(1) paměť
def fib_iter(n):
a, b = 0, 1
for _ in range(n):
a, b = b, a + b
return aBinární vyhledávání
Pro seřazené pole, O(log n):
python
def binary_search(arr, target):
low, high = 0, len(arr) - 1
while low <= high:
mid = (low + high) // 2
if arr[mid] == target:
return mid
elif arr[mid] < target:
low = mid + 1
else:
high = mid - 1
return -1Třídicí algoritmy podrobně
| Algoritmus | Best | Avg | Worst | Space | Stabilní? | In-place? |
|---|---|---|---|---|---|---|
| Bubble Sort | O(n) | O(n²) | O(n²) | O(1) | Ano | Ano |
| Insertion Sort | O(n) | O(n²) | O(n²) | O(1) | Ano | Ano |
| Selection Sort | O(n²) | O(n²) | O(n²) | O(1) | Ne | Ano |
| Merge Sort | O(n log n) | O(n log n) | O(n log n) | O(n) | Ano | Ne |
| Quick Sort | O(n log n) | O(n log n) | O(n²) | O(log n) | Ne | Ano |
| Heap Sort | O(n log n) | O(n log n) | O(n log n) | O(1) | Ne | Ano |
| Counting Sort | O(n + k) | O(n + k) | O(n + k) | O(k) | Ano | Ne |
| Radix Sort | O(d(n + k)) | O(d(n + k)) | O(d(n + k)) | O(n + k) | Ano | Ne |
Praktická volba:
- Pro malé datasety (< 50): Insertion Sort (jednoduchý, rychlý na malém)
- Pro obecné použití: Quick Sort (rychlý v praxi) nebo built-in (typicky TimSort: hybrid Merge + Insertion)
- Když potřebuješ stabilitu: Merge Sort
- Pro celočíselné klíče v omezeném rozsahu: Counting Sort, Radix Sort (umí dokonce O(n))
- Pro paměťově omezené prostředí: Heap Sort
Příklady třídění
Bubble Sort (jednoduchý, pomalý)
python
def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n - i - 1):
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]Quick Sort
python
def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quick_sort(left) + middle + quick_sort(right)Vyhledávací algoritmy
| Algoritmus | Vyžaduje | Složitost |
|---|---|---|
| Lineární | Cokoli | O(n) |
| Binární | Seřazené pole | O(log n) |
| Interpolační | Rovnoměrně rozdělená data | O(log log n) průměrně |
| Hashing | Hash tabulka | O(1) průměrně, O(n) worst |
python
# Lineární vyhledávání: O(n)
def linear_search(arr, target):
for i, x in enumerate(arr):
if x == target:
return i
return -1Rychlý tahák
| Pojem | Klíčová fakta |
|---|---|
| Algoritmus | Konečná posloupnost přesných kroků vedoucích k cíli |
| Algoritmus vs program | Abstrakce vs konkrétní implementace |
| Algoritmus vs heuristika | Garance vs odhad |
| 7 vlastností | Konečnost, resultativnost, jednoznačnost, vstupnost, obecnost, správnost, efektivnost |
| Zápis | Přirozený jazyk, pseudokód, vývojový diagram, kód |
| Iterace vs rekurze | Cyklus vs volání sebe sama (s base case) |
| Rekurze risk | Stack overflow bez base case |
| Paradigmata | Brute force, divide & conquer, dynamic programming, greedy, backtracking |
| Big O | Asymptotický horní odhad růstu |
| Časová složitost | Počet operací |
| Prostorová složitost | Spotřeba paměti |
| O(1) | Konstantní (array index, hash lookup) |
| O(log n) | Logaritmická (binární vyhledávání) |
| O(n) | Lineární (procházení pole) |
| O(n log n) | Linearitmická (efektivní třídění) |
| O(n²) | Kvadratická (Bubble Sort) |
| O(2ⁿ) | Exponenciální (brute force) |
| Quick Sort worst | O(n²) (ne O(n log n)!) |
| Stabilní třídění | Zachová pořadí stejných prvků |
| Eukleidův algoritmus | NSD dvou čísel, O(log min) |
| Binární vyhledávání | Jen seřazené pole, O(log n) |
| P vs NP | Slavný nevyřešený problém |
Tipy pro ústní zkoušku
Jak začít
"Algoritmus je konečná posloupnost přesně definovaných kroků, které vedou k vyřešení problému. Jméno pochází z perského matematika al-Chvárizmího. Algoritmy se zapisují různě: přirozeným jazykem, pseudokódem, vývojovým diagramem nebo přímo kódem v programovacím jazyce. Důležitým aspektem je algoritmická složitost, která popisuje, jak rychle rostou zdroje při větším vstupu."
Co komise typicky chce slyšet
- Definice s důrazem na konečnost a přesnost.
- Vlastnosti alespoň 5-7 hlavních.
- Způsoby zápisu s ukázkou pseudokódu.
- Iterace vs rekurze s příkladem (faktoriál).
- Big O základní třídy s příklady (O(1), O(log n), O(n), O(n log n), O(n²)).
- Konkrétní třídicí algoritmy s jejich složitostí.
Doplňky, které komisi potěší
- Původ slova z al-Chvárizmí.
- Algoritmické paradigma: divide & conquer (Merge Sort), dynamic programming (Fibonacci s cache), greedy (Dijkstra).
- Big O není jen worst case, ale asymptotický horní odhad. Existují i Ω a Θ.
- Quick Sort worst case je O(n²), ne O(n log n) (chyták).
- Stabilita a in-place vlastnosti třídění.
- Eukleidův algoritmus nebo Sito Eratosthena jako klasické příklady.
- P vs NP jako legendární nevyřešený problém.
Časté chytáky
| Otázka | Odpověď |
|---|---|
| Je Quick Sort O(n log n)? | V průměru ano, ale worst case je O(n²). Proto se používá náhodný pivot. |
| Co je base case v rekurzi? | Případ ukončení, který nevolá funkci znovu. Bez něj = stack overflow. |
| Big O = nejhorší případ? | Konvenčně ano, ale technicky Big O je horní odhad růstu, nezávisle na případu. |
| Proč Merge Sort potřebuje O(n) paměti? | Není in-place, potřebuje pomocné pole pro slučování. |
| Co je stabilní třídění? | Zachová původní pořadí prvků se stejnou hodnotou. Důležité při třídění objektů podle více klíčů. |
| Algoritmus vs program? | Algoritmus je abstraktní postup, program je konkrétní implementace v jazyce. |
| Rozdíl algoritmus a heuristika? | Algoritmus garantuje správný výsledek, heuristika je rychlejší odhad bez garance optima. |