Vzhled
11 • Normalizace databáze
Proč normalizovat?
postup návrhu relační databáze, který:
- omezuje redundanci (zbytečné duplikování údajů),
- chrání před anomáliemi při práci s daty
Anomálie - co se rozbije bez normalizace
- Update: jednu informaci musíš měnit na více místech (a někde zapomeneš)
- Insert: nejde vložit část informací bez jiné (např. zákazník bez objednávky)
- Delete: smazáním řádku omylem smažeš i informaci, kterou chceš zachovat
Co je to ACID? 🍄
ACID = vlastnosti transakcí v relačních DB (hlavně OLTP):
- A: Atomicity (Atomicita): transakce proběhne celá, nebo vůbec
- C: Consistency (Konzistence): databáze přejde z jednoho korektního stavu do jiného
- I: Isolation (Izolace): souběžné transakce se neovlivní tak, aby porušily konzistenci
- D: Durability (Trvalost): po potvrzení transakce data zůstanou zachována
OLTP vs OLAP (kde se normalizace používá)
OLTP: Online Transaction Processing
- typicky produkční aplikace (e-shop, bankovnictví, evidence)
- hodně CRUD, hodně zápisů
- důraz na konzistenci a transakce → databáze bývá více normalizovaná
- nevýhoda: pro čtení často více JOINů (může být pomalejší na složité dotazy)
OLAP: Online Analytical Processing
- analytika, reporting
- data jsou „připravená“, často ve velkých tabulkách
- důraz na rychlé čtení a agregace → častá denormalizace (méně JOINů)
Myšlenka: data primárně zapisuješ do OLTP, pak se pravidelně přesouvají/transformují do OLAP, odkud se hlavně čte
Normalizace vs. optimalizace
- Normalizace - více tabulek, více vazeb, méně duplicity, vyšší konzistence ⚠️ často více JOINů - čtení může být pomalejší
- Optimalizace → některé tabulky se účelově „vrací zpět dohromady“ kvůli výkonu ⚠️ risk duplicity → musíš hlídat konzistenci
V praxi je databáze často kombinace obojího.
Základní pojmy:
primární klíč (PK): sloupec/sloupce jednoznačně identifikující řádek
kandidátní klíč: minimální množina atributů, která umí jednoznačně určit řádek
složený klíč: kandidátní/primární klíč z více sloupců
neklíčový atribut: atribut, který není součástí žádného kandidátního klíče v tabulce
funkční závislost:
X → Yznamená „hodnota X určuje hodnotu Y“
Normální formy (1NF až 3NF + BCNF)
0. NF - nenormalizovaná tabulka (neoficiálně)
„Všechno v jedné tabulce“, často:
- vícenásobné hodnoty v jednom sloupci (seznamy)
- opakující se skupiny
- míchání více entit dohromady
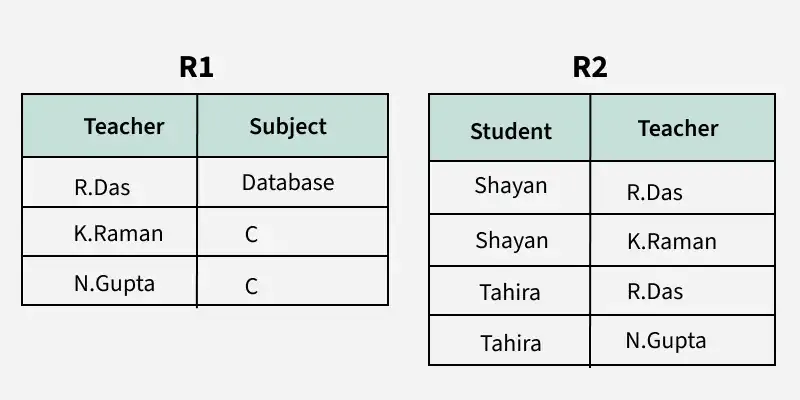
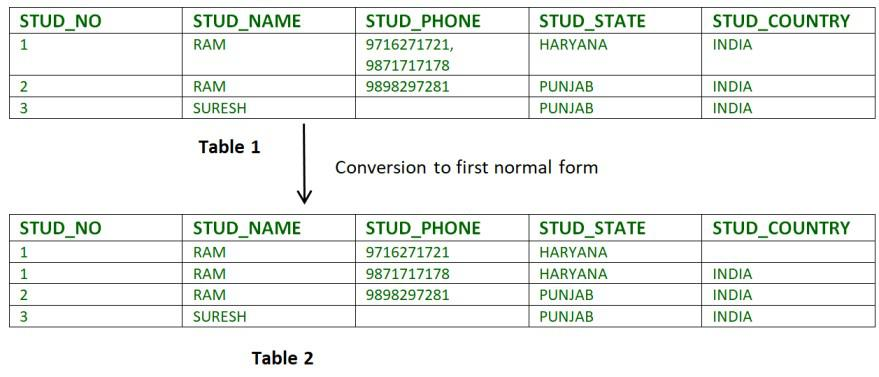
1. NF - první normální forma: atomické hodnoty
Tabulka je v 1NF, když:
- každý sloupec obsahuje jednu atomickou hodnotu (ne seznam, ne „více věcí v jednom“),
- žádné opakující se skupiny v řádku.
Typická chyba:
Name = "Honza Hyxa"(mix dvou údajů v jednom poli)
Oprava:
FirstName,LastName
nebo když je to potřeba, vytvořit samostatné entity/tabulky (např. více telefonů):
Person(person_id, ...)PersonPhone(person_id, phone)
- NF graficky:
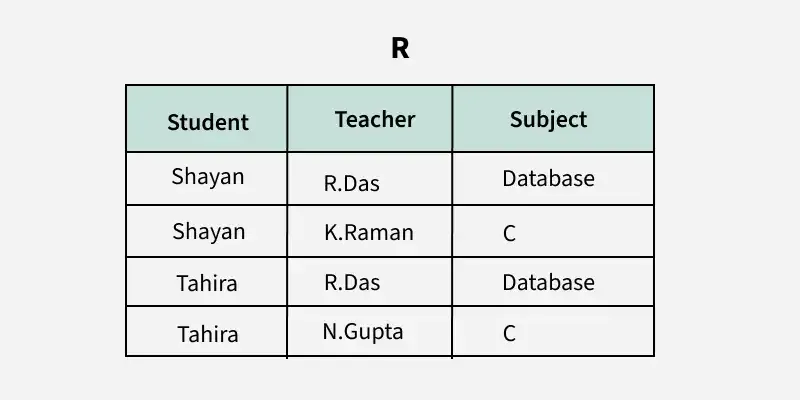
2. NF - druhá normální forma: závislost na celém klíči
Platí:
- tabulka je v 1NF,
- každý neklíčový atribut závisí na celém kandidátním klíči,
- hlavně řeší částečné závislosti u složených klíčů
příklad porušení 2NF:OrderItem(order_id, product_id, product_name, quantity)
klíčem je (order_id, product_id)
product_name závisí jen na product_id = porušení 2NF.
Oprava:
Product(product_id, product_name, ...)OrderItem(order_id, product_id, quantity)
- NF graficky:
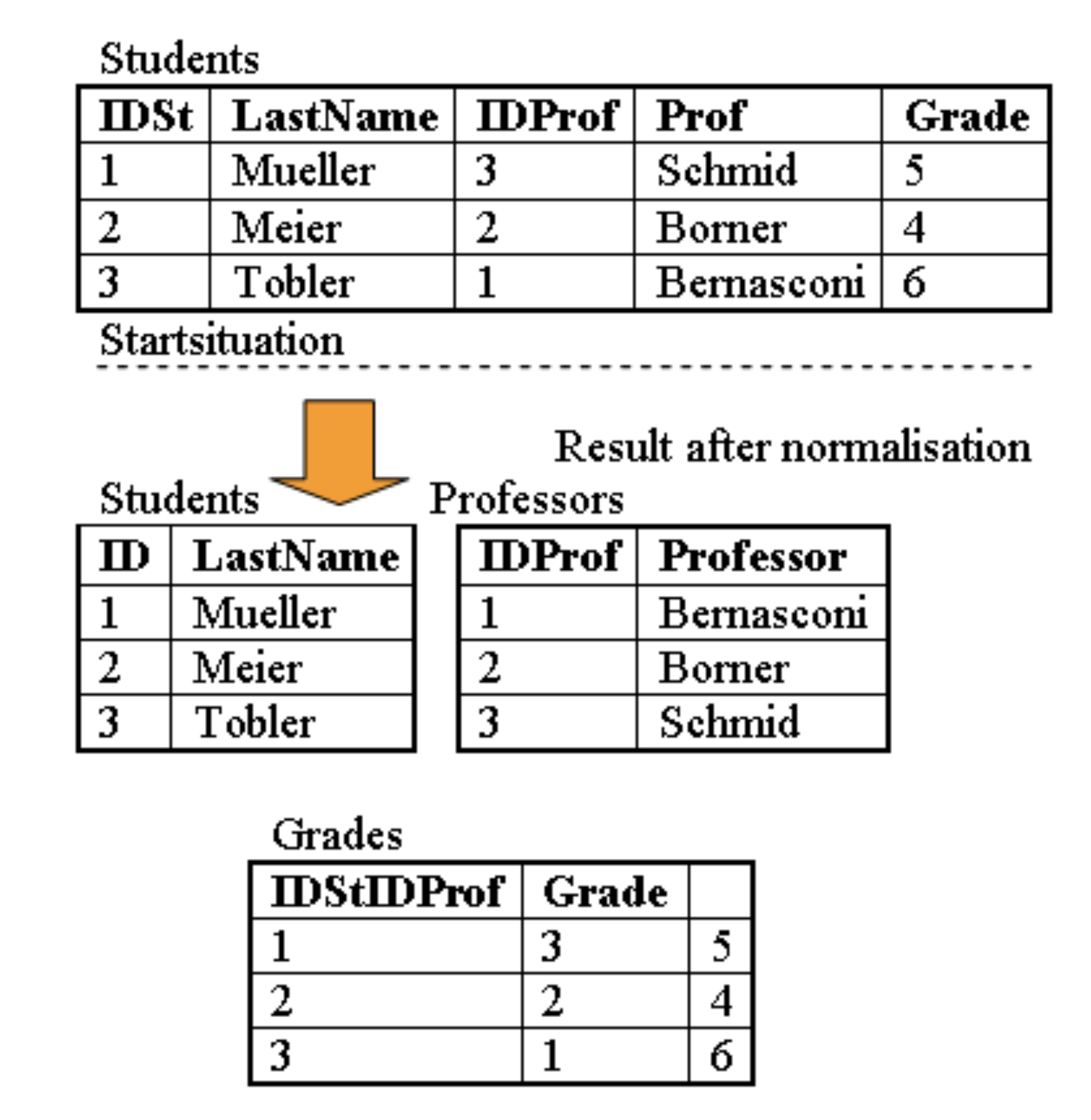
3. NF - třetí normální forma: bez tranzitivních závislostí
Platí:
- tabulka je ve 2. NF
- neklíčové atributy nezávisí na jiných neklíčových (žádná tranzitivní závislost)
Tranzitivní závislost:PK → A a zároveň A → B (kde A není klíč)
→ pak PK → B „přes A“ a to v jedné tabulce nechceme
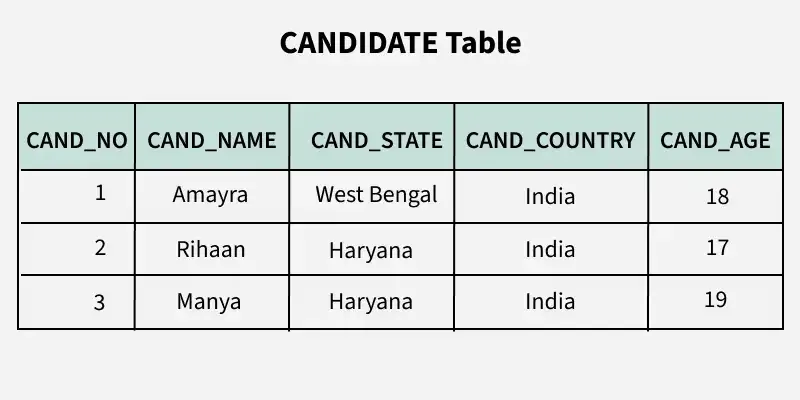
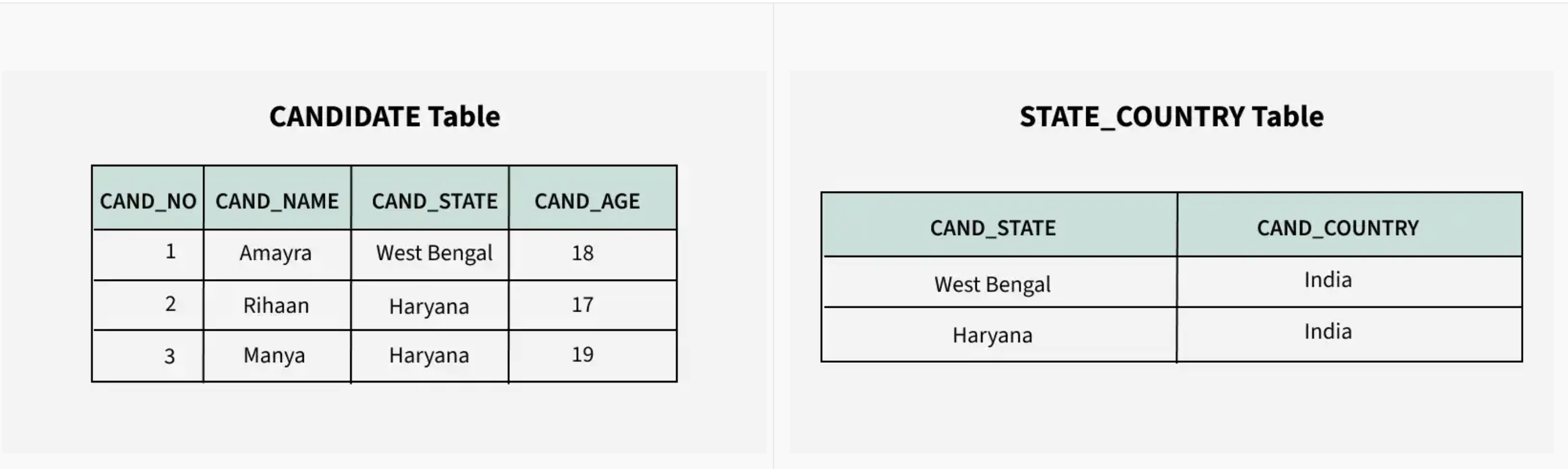
příklad porušení 3NF:Employee(employee_id, dept_id, dept_name)
dept_name závisí na dept_id, a dept_id na employee_id → tranzitivně.
Oprava:
Department(dept_id, dept_name)Employee(employee_id, dept_id, ...)
- NF graficky:
BCNF - Boyce-Coddova normální forma (silnější než 3NF)
BCNF řeší „vzácnější situace“ - typicky, když:
- existuje více kandidátních klíčů,
- a vznikají závislosti, které 3NF ještě „pustí“, ale BCNF už ne.
definice (stručně):
Pro každou netriviální funkční závislost X → Y musí platit, že X je superklíč.
BCNF: